


This blog is about my work on the Postgres open source database, and is published on Planet PostgreSQL. PgLife allows monitoring of all Postgres community activity.
Online status:
Unread Postgres emails:
Email graphs:
incoming,
outgoing,
unread,
commits
(details)
 Enterprise Postgres Growth in Japan
Enterprise Postgres Growth in Japan
Wednesday, November 17, 2021
I presented a new slide deck, Enterprise Postgres Growth in Japan, at last week's Japan PostgreSQL User Group (jpug) conference. I have been closely involved with the Japanese Postgres community for 20 years, and distilling lessons from my involvement was challenging. However, I was very happy with the result, and I think the audience benefited. I broke down the time into three periods, and concluded that the Japanese are now heavily involved in Postgres server development, and the community greatly relies on them.
View or Post Comments Four New Presentations
Tuesday, August 3, 2021
I have been busy during the past few months and wrote four new presentations:
- Upcoming PostgreSQL Features highlights the features I consider most important in Postgres 14.
- Learning To Share: Creating and Delivering Effective Presentations gives guidance on effective presentations.
- Data Horizons With Postgres explains how modern data storage needs have moved beyond pure relational systems.
- Producing Quality Software explains the forces in organizations that promote quality software.
The first three presentations have video recordings.
Another big change is that I have converted all of my slides from the 4:3 aspect ratio to the more modern 16:9. The wider format allows long lines of computer text to use larger fonts with less line wrapping. I have also converted some of my slides to use a two-column layout to take advantage of the wider format. My presentation selection page has also been improved to make talk selection easier, and to display slide, presentation, and video counts.
View or Post Comments Why Vacuum?
Why Vacuum?
Monday, June 21, 2021
Vacuum is a routine database maintenance task that is handled manually or by autovacuum. Over the years, people have wondered if there is a way to eliminate the vacuum requirement.
First, since autovacuum is enabled by default, most sites don't even need to know that vacuum is running, and that is a key feature — vacuum tasks always run in the background, not as part of foreground queries like insert or update. (There are a few cleanup operations that are so inexpensive that they are even performed by select queries.) By having vacuum tasks run in the background, foreground queries are almost never affected by vacuum, except perhaps by vacuum i/o requirements. Second, vacuum improves code simplicity by centralizing vacuum tasks in a single set of processes. Third, since Postgres does not have an undo segment, there is no centralized place where changes must be recorded, improving database concurrency.
So, we keep improving vacuum, its performance, and its minimal interference with foreground queries, but it is hard to see how it can be fundamentally improved without adding many negatives.
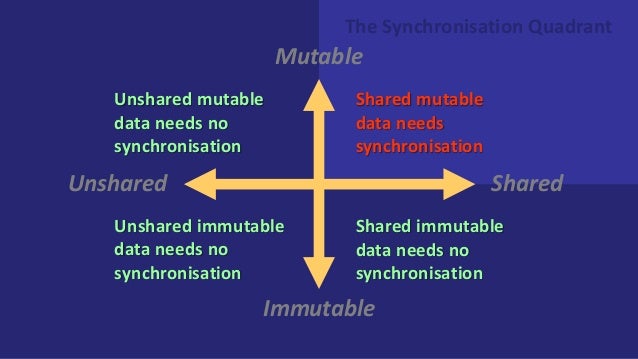
View or Post Comments The Hard Quadrant
The Hard Quadrant
Wednesday, June 16, 2021
Having worked with databases for 32 years, I have always lived in a world of locks, sharing, and complexity, but sometimes, I look out the window and wonder, "Why does everything have to be so hard?" After a while, I just give up figuring it out and get back to work.
However, a few months ago I watched a video that gave me a new perspective on that question. The video was "The Forgotten Art of Structured Programming" by
Kevlin Henney, and was given on a C++-themed cruise. (Postgres needs one of those someday.  ) Anyway, the
interesting part starts at 1:22:00, and this
slide holds the key to the complexity I could not
previously express.
) Anyway, the
interesting part starts at 1:22:00, and this
slide holds the key to the complexity I could not
previously express.
Kevlin explains that database programming is hard because shared, mutable state is hard. If data is immutable or not shared, things are much easier. This means that no matter what new magical tool or language is created, database programming will continue to be hard, and I just have to accept that. One comforting discovery is that someone else had the same reaction to that slide, which makes me feel better.
View or Post Comments Reducing Planned Downtime Can Increase Unplanned Downtime
Monday, June 14, 2021
I mentioned the problem of safety systems causing safety failures last year. There is a corollary to that which I want to mention related to planned vs unplanned database downtime.
Databases are critical parts of most information technology infrastructure, so downtime is a big concern. There are a few cases where you know your Postgres database will need to be down, if only briefly
- Operating system upgrades
- Minor database upgrades
- Major database upgrades
- Application upgrades
You can reduce the downtime duration of these operations by using replica servers, but there is still the complexity of session migration during switchover. Multi-master replication can simplify application switchover, but it can also have a higher probability of unplanned downtime if its complex systems fail.
My point is that the closer you try to get to zero planned downtime, the more complex the solutions and the more likelihood of unplanned downtime due to complexity.
View or Post Comments Features Move into the Database as they Mature
Friday, June 11, 2021
Relational databases started as simple data containers with a relational structure. Over the decades, sql matured into a language that allows complex processing inside relational databases. The typical life-cycle is that once a client-side feature becomes well-understood and established, it often moves into a relational database for efficiency and consistency among applications. This has happened for data warehouse workloads (slide 30), full text search, geographic information systems (gis), non-relational workloads, and json. Odds are this migration will continue. Artificial intelligence might be the next area of integration.
View or Post Comments Looking Back at Postgres
Wednesday, June 9, 2021
Postgres history goes back 35 years, and it is always interesting for me to hear details about the early years and the project decisions that were made. Fortunately, Joseph M. Hellerstein, the author of GiST, has written and released a public copy of his recollections, which are part of a larger book about Michael Stonebraker. This quote summarizes the paper:
The signature theme of Postgres was the introduction of what he eventually called Object-Relational database features: support for object-oriented programming ideas within the data model and declarative query language of a database system. But Stonebraker also decided to pursue a number of other technical challenges in Postgres that were independent of object-oriented support, including active database rules, versioned data, tertiary storage, and parallelism.
Hellerstein explains how each of these features developed during the Berkeley years, and often adds how they were later enhanced by the PostgreSQL project. He closes by analyzing the reasons for the success of the PostgreSQL project and its impact on the database industry.
View or Post Comments Time Zone Abbreviations
Time Zone Abbreviations
Monday, June 7, 2021
Postgres is a convenient platform to manage and manipulate date and timestamp information, and included in that is the ability to manage time zones. Postgres can be compiled to use pre-installed time zone definitions, or --with-system-tzdata can be used to specify an external time zone definition directory.
Once installed, the system view pg_timezone_names can report the supported time zones:
SELECT * FROM pg_timezone_names ORDER BY name LIMIT 5;
name | abbrev | utc_offset | is_dst
--------------------+--------+------------+--------
Africa/Abidjan | GMT | 00:00:00 | f
Africa/Accra | GMT | 00:00:00 | f
Africa/Addis_Ababa | EAT | 03:00:00 | f
Africa/Algiers | CET | 01:00:00 | f
Africa/Asmara | EAT | 03:00:00 | f
and pg_timezone_abbrevs can report the supported time zone abbreviations:
SELECT * FROM pg_timezone_abbrevs ORDER BY abbrev LIMIT 5; abbrev | utc_offset | is_dst --------+------------+-------- ACDT | 10:30:00 | t ACSST | 10:30:00 | t ACST | 09:30:00 | f ACT | -05:00:00 | f ACWST | 08:45:00 | f
For most users, the supported time zone names are sufficient, but time zone abbreviations are very location-specific. Fortunately, Postgres gives users the ability to customize time zone abbreviations.
View or Post Comments Storing Signatures in Databases
Storing Signatures in Databases
Friday, June 4, 2021
I wrote a blog entry in 2018 about how to sign data rows so their authenticity can be verified by anyone using a public key. In talking to Chapman Flack, he mentioned that another option is to store data signatures in the database even if the data is stored outside the database. This allows the database to serve as a central location to verify the authenticity of externally-stored data. This is particularly useful if you trust your database storage but not your external storage.
View or Post Comments Pgsodium
Wednesday, June 2, 2021
I created pg_cryptokey in 2019, which allows encryption key management at the sql-level. A more sophisticated project is pgsodium, which uses libsodium for encryption and decryption. It is similar to pgcrypto, but has key management like pg_cryptokey. If you have ever wanted pgcrypto with integrated key management, pgsodium is definitely worth considering.
View or Post Comments Encrypting pgpass
Encrypting pgpass
Friday, May 28, 2021
Libpq, and all the interfaces that use it, can use a pgpass file to centrally store database connection parameters. Unfortunately, one big security issue with this feature is that the file, which can include passwords, is stored unencrypted in the file system. This email thread discussed the idea of encrypting this file, with some interesting approaches to improving security:
- encrypt the file system where the file is stored
- decrypt the password file, let libpq access it, and delete the file
- use environment variables
- use ssl certificates, not passwords
Maybe allowing the pgpass file to be read from the output of a command would be a good security enhancement.
View or Post Comments Encrypting Logical Backups
Wednesday, May 26, 2021
Pg_dump and pg_dumpall are used to create logical database dumps. Pg_dump does single-database backups, while pg_dumpall does full-cluster backups.
Last year, someone asked a very good question about how to encrypt such backups. While pg_dump supports compression internally, it doesn't support encryption. The first suggestion was to send the backup output to a program that performs symmetric encryption. However, the challenge of using symmetric encryption is key protection — the encryption and decryption key are the same, so if someone has access to the backup encryption key, they can also decrypt the backup. It is especially difficult to protect backups since they are often automated.
The final email gives the best suggestion — to use public-key encryption. This allows the public/encryption key to be safely embedded in backup scripts without requiring access to the private/decryption key. The private/decryption key must be accessed only during recovery. I guess the same is true for any backup method.
View or Post Comments Postgres 14 Release Notes
Postgres 14 Release Notes
Monday, May 24, 2021
Postgres 14 Beta 1 was released last week. There are two notable things about this release. First, feature count — while the past four years have had major release note feature counts in the 170–189 range, this release has 222. This is similar to the count for pre-2017 releases.
Second, the most current version of the release notes is not available on the postgresql.org website, not even in the developer documentation build. The release notes listed under 14 beta use the version that was current when beta1 was packaged.
The easiest way to see the most current release notes, including links to each feature, is on my local documentation build. You can also download the prebuilt documentation using the nightly development snapshot and open the file doc/src/sgml/html/release-14.html in a web browser. (This will no longer work once we create a Postgres 14 git branch.) Each beta and release candidate will continue to use the release note version that was current at the time of packaging. Also, if you are curious about the commits that happened since beta1, you can click on the plus sign after "14 beta1" on the pglife website.
View or Post Comments Postgres Pulse
Monday, May 17, 2021
During 2020, edb created a 14-part series of 30-minute videos discussing various Postgres topics. Its goal was to tackle some of the more complex issues that are hard to explain in writing, but easy to explain when experts get together and exchange ideas. The result was Postgres Pulse, and the video recordings are currently online. I enjoyed being part of the discussions, and learned a lot about how complex some of these topics can be.
View or Post Comments Optimization Aggressiveness
Optimization Aggressiveness
Friday, May 14, 2021
Optimizing compilers allow users to control how hard the compiler will work to produce efficient cpu instructions, e.g., -O, -O3. Postgres also has an optimizer, but there is limited control over its aggressiveness in generating efficient plans for the executor.
The default behavior of the Postgres optimizer is considered to be sufficient for almost all queries, both oltp and olap. Postgres does have the ability to automatically reduce the aggressiveness of the optimizer for queries with many tables. These queries are known to cause the optimizer to take a pathological amount of time, perhaps more than the time required to execute even less-optimized queries. It is easy to enable the solution for this problem, called the Genetic Query Optimizer (geqo), because it is a well-known problem, and it is easy to detect if the problem could happen by counting the number of tables listed in the from clause. From_collapse_limit and join_collapse_limit can also prevent the inefficient increase in the number of tables processed by each from clause, and hence the plan/optimization duration.
There are a few options for increasing the aggressiveness of the optimizer, and potentially increasing plan creation time. Just-in-Time Compilation (jit) enables a completely new way of processing expressions and row formation. There are three jit costs that control when its optimizations are enabled. Constraint_exclusion can also be increased and decreased in its aggressiveness.
However, areas still exist where we are challenged in adding optimizations:
- The queries that can benefit from the optimization are rare.
- Detecting the applicability of the optimization is expensive.
- The speed benefit of the optimization is minimal.
We occasionally get requests for such missing optimizations, but often the answer from our server developer community is that adding an optimization for this type of query would slow down the optimizer too much for general queries.
I think eventually our community will need to allow users to enable more enhanced optimizations when users know their sql queries are likely to benefit from specialized optimizations, or even better, automatically enable such optimizations when it is clear the query will be expensive and therefore the optimization duration will be less significant. Because execution time is heavily dependent on the size of tables and the existence of indexes, the full cost of the query is often unknown until the end of the optimization stage, when it is often too late to perform specialized optimizations. Some specialized optimizations might require the full optimization of the query, and if the cost is high, a full re-optimization of the query using more aggressive optimization methods.
View or Post Comments Hash Aggregation
Hash Aggregation
Wednesday, May 12, 2021
Hash aggregation has always confused me. I know what hash joins are, and even wrote about it, and I know what aggregates are. So, what is hash aggregation? Is it a hash join that uses an aggregate function?
Well, no. Hash aggregates allow accumulation/aggregation of duplicate values or removal of duplicate values. There are four ways to perform this
aggregation, as listed in AggStrategy:
- Plain: simple agg across all input rows
- Sorted: grouped agg, input must be sorted
- Hashed: grouped agg, use internal hashtable
- Mixed: grouped agg, hash and sort both used
The first option does not retain or "pass upward in the executor plan" any individual values. The second option processes the rows in order, allowing easy accumulation or removal of duplicate values. The last two use hash aggregation, that is accumulation or removal of duplicates using hashing. Hashing aggregation is used to perform group by, distinct, and union (without all) processing.
Internally, how is hash aggregation performed? Prior to Postgres 13, hash aggregation could only create hash structures in memory, so was only used when the number of distinct hash values was expected to be small. In Postgres 13, hash aggregates can spill to disk — this allows hash aggregation to be used by many more queries.
View or Post Comments Clustering a Table
Monday, May 10, 2021
Having written over 600 blog entries, I thought I would have already covered the complexities of the
cluster command, but it seems I have not, so let's do that now.
Cluster is an unusual sql command because, like non-unique create index, it only affects performance. In fact, cluster requires the existence of an index. So, what does cluster do? Well, what does create index do? Let's look at how storage works in Postgres.
User data rows are stored in heap files in the file system, and those rows are stored in an indeterminate order. If the table is initially loaded in insert/copy order, later inserts, updates, and deletes will cause rows to be added in unpredictable order in the heap files. Create index creates a secondary file with entries pointing to heap rows, and index entries are ordered to match the values in the columns specified in the create index command. By quickly finding desired values in the index, index pointers can be followed to quickly find matching heap rows.
For most cases, creating indexes is sufficient to yield acceptable performance. However, there are a few cases where having the index ordered, but the heap unordered, causes major performance problems. This is where cluster becomes useful — it orders the heap to match the ordering of one of its indexes. (Some non-btree indexes can't be clustered because they lack linear ordering.)
How can this heap ordering improve performance? Well, if you are looking for only one row, it doesn't really matter where it is in the heap file — it is only going to take one heap access to retrieve it. However, suppose you are retrieving one-hundred rows matching an indexed column? Well, we can find the one-hundred matching index entries quickly, but what about the one-hundred heap rows? If they are scattered on one-hundred 8kB heap pages, that requires many i/o accesses. But what if the matching heap rows are on adjacent heap pages — that reduces the number of heap pages needed. If those heap pages are all in memory, it might not matter, but if some are on storage, reducing the number of heap accesses can yield significant performance benefits.
When does heap ordering help performance? I can think of three cases:
- Accessing a single indexed value that has many duplicates, e.g., col = 5 where there are many matching values
- Accessing a range of values, e.g., col >= 10 AND col < 20
- Accessing values that are frequently accessed by other sessions, e.g., unpaid invoice rows
For these workloads, ordering the heap can greatly reduce the number of heap accesses.
However, there are two big downsides to using cluster. First, while the cluster command is creating a new heap file ordered to match an index, no other sessions can read or write the table. Second, unlike index-organized tables (which Postgres does not support since they have serious downsides), the heap does not remain clustered — later insert and update operations will place rows in indeterminate order in the heap, causing the heap to become less ordered over time — a later cluster operation will be required to restore ideal ordering. (A non-default heap fill factor can improve update locality.) Fortunately, cluster does remember previous cluster operations and can automatically restore ideal clustering to all tables that have been previously clustered.
Let's see how explain makes use of heap rows being ordered. Actually, this is independent of the cluster command — Postgres maintains an indication of how ordered the heap is based on every column, and potentially expression indexes, not just columns involved in previous cluster operations. Cluster is really just a way of forcing heap ordering, but heap ordering might happen naturally based on the order of operations, and Postgres can take advantage of that.
In the example below, the rows are automatically ordered because of their insert order, and queries on pg_stats and pg_statistic verify the correlation is one:
-- use a second column so index-only scans are not used, and so the row has a typical length
CREATE TABLE public.cluster_test (x INTEGER, y TEXT);
CREATE INDEX i_cluster_test ON cluster_test (x);
INSERT INTO public.cluster_test
SELECT *, repeat('x', 250) FROM generate_series(1, 100000);
-- compute correlation statistics
ANALYZE cluster_test;
-- uses view pg_stats
SELECT correlation
FROM pg_stats
WHERE schemaname = 'public' AND tablename = 'cluster_test' AND attname = 'x';
correlation
-------------
1
-- uses table pg_statistic, the SQL is from psql's '\d+ pg_stats'
SELECT CASE
WHEN stakind1 = 3 THEN stanumbers1[1]
WHEN stakind2 = 3 THEN stanumbers2[1]
WHEN stakind3 = 3 THEN stanumbers3[1]
WHEN stakind4 = 3 THEN stanumbers4[1]
WHEN stakind5 = 3 THEN stanumbers5[1]
ELSE NULL::real
END AS correlation
FROM pg_namespace JOIN pg_class ON (pg_namespace.oid = relnamespace)
JOIN pg_attribute ON (pg_class.oid = pg_attribute.attrelid)
JOIN pg_statistic ON (pg_class.oid = starelid AND pg_attribute.attnum = staattnum)
WHERE nspname = 'public' AND relname = 'cluster_test' AND attname = 'x';
correlation
-------------
1
EXPLAIN SELECT * FROM cluster_test WHERE x < 74000;
QUERY PLAN
--------------------------------------------------------------------------------------------
Index Scan using i_cluster_test on cluster_test (cost=0.29..4841.80 rows=73743 width=258)
Index Cond: (x < 74000)
EXPLAIN SELECT * FROM cluster_test WHERE x < 75000;
QUERY PLAN
---------------------------------------------------------------------
Seq Scan on cluster_test (cost=0.00..4954.00 rows=74752 width=258)
Filter: (x < 75000)
You can see the Postgres optimizer switches from index scan to sequential scan between 74k and 75k row accesses. This next example inserts the rows in random order, which yields a correlation near zero, and a lower value to stop using an index, i.e., 28k vs. 75k:
-- use a second column so index-only scans are not used
DELETE FROM public.cluster_test;
CREATE INDEX i_cluster_test ON cluster_test (x);
INSERT INTO public.cluster_test
SELECT *, repeat('x', 250) FROM generate_series(1, 100000) ORDER BY random();
-- compute correlation statistics
ANALYZE cluster_test;
-- uses view pg_stats
SELECT correlation
FROM pg_stats
WHERE schemaname = 'public' AND tablename = 'cluster_test' AND attname = 'x';
correlation
---------------
-0.0048559047
EXPLAIN SELECT * FROM cluster_test WHERE x < 3;
QUERY PLAN
--------------------------------------------------------------------------------------
Index Scan using i_cluster_test on cluster_test (cost=0.42..12.45 rows=2 width=258)
Index Cond: (x < 3)
(2 rows)
EXPLAIN SELECT * FROM cluster_test WHERE x < 4;
QUERY PLAN
-----------------------------------------------------------------------------
Bitmap Heap Scan on cluster_test (cost=4.44..16.30 rows=3 width=258)
Recheck Cond: (x < 4)
-> Bitmap Index Scan on i_cluster_test (cost=0.00..4.44 rows=3 width=0)
Index Cond: (x < 4)
EXPLAIN SELECT * FROM cluster_test WHERE x < 27000;
QUERY PLAN
-----------------------------------------------------------------------------------
Bitmap Heap Scan on cluster_test (cost=809.99..8556.02 rows=27042 width=258)
Recheck Cond: (x < 27000)
-> Bitmap Index Scan on i_cluster_test (cost=0.00..803.23 rows=27042 width=0)
Index Cond: (x < 27000)
EXPLAIN SELECT * FROM cluster_test WHERE x < 28000;
QUERY PLAN
---------------------------------------------------------------------
Seq Scan on cluster_test (cost=0.00..8658.00 rows=28058 width=258)
Filter: (x < 28000)
Notice that it switches from an index scan to a bitmap heap scan after three rows because statistics indicate that the matching rows are stored randomly in the heap. When using an index whose heap ordering closely matches the index ordering, there is no value in using a bitmap heap scan compared to an index scan.
Using cluster, we can force the heap to match the index ordering, and again cause the index to be used for a larger number of rows:
CLUSTER cluster_test USING i_cluster_test;
ANALYZE cluster_test;
EXPLAIN SELECT * FROM cluster_test WHERE x < 74000;
QUERY PLAN
--------------------------------------------------------------------------------------------
Index Scan using i_cluster_test on cluster_test (cost=0.29..4836.03 rows=73642 width=258)
Index Cond: (x < 74000)
EXPLAIN SELECT * FROM cluster_test WHERE x < 75000;
QUERY PLAN
---------------------------------------------------------------------
Seq Scan on cluster_test (cost=0.00..4954.00 rows=74696 width=258)
Filter: (x < 75000)
Of course, explain only estimates the most efficient way to retrieve data — proper performance testing is required to determine when cluster is helpful.
Time-series data can be difficult to use with cluster. The most recent data is usually the most frequently accessed. If the table has few updates and deletes, new rows are typically appended to the end of the file, giving good correlated ordering which can be detected and exploited by Postgres. However, if there are many updates/deletes, inserted and updated rows could be placed in unused space anywhere in the table, so correlation would be low. In fact, if you previously clustered the table, and you are only accessing recent data, you might get an unrepresentatively-high correlation value and inefficient plans because, while most of the table rows are clustered, the new rows, which are the ones most frequently accessed, are not ordered to match an index. Table partitioning can be thought of as a crude clustering, which can help with these workloads by improving data locality using time-based partitions. Anyway, hopefully this blog post has given you some tips on when clustering can be useful.
View or Post Comments Postgres on Big Iron
Postgres on Big Iron
Friday, May 7, 2021
Postgres has always run well on commodity hardware, and works well on Raspberry Pi and consumer devices too. However, we have always lagged in optimizing Postgres on very large hardware, mostly because our community has limited access to such hardware. In recent years, Postgres support companies have given the community access to large hardware, and run performance tests themselves, which has allowed the community to enhance Postgres for such hardware. However, since typical workloads do not use large hardware, there is always a lag in how quickly Postgres can adjust to ever-large hardware platforms.
This email report from July of 2020 is about a server actively using 5k tables. When there are only a few hundred connections, basically 2–3x the number of cpus, the system works fine, but the system experiences a steep performance decline as thousands of active connections try to issue queries. Whether the thousands of connections happen because of increased user demand or increased slowness due to the number of active connections is unclear. The email thread suggests various lock table and autovacuum improvements that might improve the situation, but there is no clear conclusion. One bright spot is that two weeks after this report, another report complained about the performance of autovacuum in a database with many tables, and supplied a patch which was applied in December and will be in Postgres 14.
Ideally we would have been able to test this patch against the workload reported in the July email to see if it fixes the problem. However, it is difficult to get the patch into production use, or get a test server of suitable size and produce a workload that matches the report. This is why it is much slower to improve the performance of large systems compared to simple workloads on commodity hardware — we make progress, but it is slower.
View or Post Comments Set of Record
Set of Record
Wednesday, May 5, 2021
I previously covered the use of jsonb_to_record(), which uses record types to cast multiple json values. Record types are effectively special sql rows.
There is an even more complicated sql type called set of record. It is a set of records, or set of rows. While the record type allows you to create a row with multiple columns, set of record allows you to create multiple rows, each having multiple columns. If you do \dfS in psql, you will see many functions defined as accepting or returning record values, and many returning set of record values, particularly database system information functions, e.g., pg_get_keywords().
As an example, the unnest function converts an array to a list of rows, effectively a set of records:
SELECT unnest(ARRAY[1,2]);
unnest
--------
1
2
SELECT * FROM unnest(ARRAY[1,2]);
unnest
--------
1
2
test=> SELECT * FROM unnest(ARRAY[1,2], ARRAY[3, 4]) AS x (a, b);
a | b
---+---
1 | 3
2 | 4
While the single-column unnest can be done in the target list, without a from, multi-column rows/records do require a from clause. One other popular set of record-returning function is generate_series.
View or Post Comments Jsonb Multi-Column Type Casting
Jsonb Multi-Column Type Casting
Monday, May 3, 2021
I already covered jsonb type casting of single values. However, if you are extracting multiple values from jsonb that casting method can be cumbersome, and it also has limitations. Fortunately, there is another way — a way to retrieve multiple jsonb or json values and cast everything in one location.
Here is a simple table taken from my previous blog post:
CREATE TABLE test(x JSONB);
INSERT INTO test VALUES ('{"a": "xyz", "b": 5}');
Previously, to cast the first column as an sql text data type and the second column as integer, we would have to do:
SELECT (x->'a')::TEXT, (x->'b')::INTEGER FROM test; text | int4 -------+------ "xyz" | 5
though this can be done more simply using ->>, which also removes the double-quotes:
SELECT x->>'a', (x->'b')::INTEGER FROM test; ?column? | int4 ----------+------ xyz | 5
Using jsonb_to_record(), it can be simplified to:
SELECT a, b, pg_typeof(a) AS a_type, pg_typeof(b) AS b_type FROM test, jsonb_to_record(test.x) AS x (a TEXT, b INTEGER); a | b | a_type | b_type -----+---+--------+--------- xyz | 5 | text | integer
As you can see, the casting of both columns is done in one place. Of course, this casting method becomes more useful the more columns you have to cast.
Jsonb and json columns allow the creation of data rows inside of columns, unconstrained by the requirement of consistent column names or data types across rows. Effectively, the query above creates query-scoped relation x to extract columns from the "row inside a column" jsonb column x. Query-scoped relation columns x.a and x.b are the values of the two json keys (a, b) we wish to extract. The casts are happening as the values are extracted from the jsonb column, meaning that any reference to the query-scoped columns, e.g., in a where clause, will use the casted data types. For example, you can see in the queries below that b is treated as an integer:
SELECT x.a, b, pg_typeof(a) AS a_type, pg_typeof(b) AS b_type FROM test, jsonb_to_record(test.x) AS x (a TEXT, b INTEGER) WHERE b <= 4; a | b | a_type | b_type ---+---+--------+-------- SELECT x.a, b, pg_typeof(a) AS a_type, pg_typeof(b) AS b_type FROM test, jsonb_to_record(test.x) AS x (a TEXT, b INTEGER) WHERE b > 4; a | b | a_type | b_type -----+---+--------+--------- xyz | 5 | text | integer
While creating query-scoped relations might be overkill for simple casts that can be done in the target list, more complex cases easily benefit from query-scoped relations. Query-scoped relations are also useful for multi-key json access, because json stores the keys/values as text and the function parses it only once, even if multiple keys are requested. These email threads (1, 2) cover more of the details.
View or Post Comments Separating Cluster and Database Attributes
Separating Cluster and Database Attributes
Friday, April 30, 2021
I have already covered the use of clusters, databases, and schemas, but a recent email thread highlighted the complexity of restoring database attributes and the objects inside of databases. In summary, create database copies the contents of databases, but not their attributes, except for database attributes that are tied to the database contents, like collation and encoding. The thread ends with application of a documentation patch that mentions that database-level permissions are also not copied. Thanks to Tom Lane for clarifying this issue.
View or Post Comments Release Size Analysis, The 2021 Edition
Release Size Analysis, The 2021 Edition
Wednesday, April 28, 2021
In 2011, I wrote a query to analyze the sizes of all the major Postgres releases, so I thought it was time to update it with the results below:
version | reldate | months | changes | C lines | C changes | % C change ----------+------------+--------+---------+---------+-----------+------------ 4.2 | 1994-03-17 | | | 250872 | | 1.0 | 1995-09-05 | 18 | | 172470 | -78402 | -31 1.01 | 1996-02-23 | 6 | | 179463 | 6993 | 4 1.09 | 1996-11-04 | 8 | | 178976 | -487 | 0 6.0 | 1997-01-29 | 3 | | 189399 | 10423 | 5 6.1 | 1997-06-08 | 4 | | 200709 | 11310 | 5 6.2 | 1997-10-02 | 4 | | 225848 | 25139 | 12 6.3 | 1998-03-01 | 5 | | 260809 | 34961 | 15 6.4 | 1998-10-30 | 8 | | 297918 | 37109 | 14 6.5 | 1999-06-09 | 7 | | 331278 | 33360 | 11 7.0 | 2000-05-08 | 11 | | 383270 | 51992 | 15 7.1 | 2001-04-13 | 11 | | 380642 | -2628 | 0 7.2 | 2002-02-04 | 10 | 250 | 425898 | 45256 | 11 7.3 | 2002-11-27 | 10 | 305 | 439816 | 13918 | 3 7.4 | 2003-11-17 | 12 | 263 | 522371 | 82555 | 18 8.0 | 2005-01-19 | 14 | 230 | 586127 | 63756 | 12 8.1 | 2005-11-08 | 10 | 174 | 625253 | 39126 | 6 8.2 | 2006-12-05 | 13 | 215 | 684726 | 59473 | 9 8.3 | 2008-02-04 | 14 | 214 | 765100 | 80374 | 11 8.4 | 2009-07-01 | 17 | 314 | 817849 | 52749 | 6 9.0 | 2010-09-20 | 15 | 237 | 870790 | 52941 | 6 9.1 | 2011-09-12 | 12 | 203 | 932936 | 62146 | 7 9.2 | 2012-09-10 | 12 | 238 | 987460 | 54524 | 5 9.3 | 2013-09-09 | 12 | 177 | 1040813 | 53353 | 5 9.4 | 2014-12-18 | 15 | 211 | 1096707 | 55894 | 5 9.5 | 2016-01-07 | 13 | 193 | 1167110 | 70403 | 6 9.6 | 2016-09-29 | 9 | 214 | 1219720 | 52610 | 4 10 | 2017-10-05 | 12 | 189 | 1316447 | 96727 | 7 11 | 2018-10-18 | 12 | 170 | 1369590 | 53143 | 4 12 | 2019-10-03 | 11 | 180 | 1423215 | 53625 | 3 13 | 2020-09-24 | 12 | 178 | 1473738 | 50523 | 3 Averages | | 11 | 219 | | | 6.03
While the average change in the number of lines of code per release over the life of the project is 6.70%, the average for the last ten years is 4.67%. This is probably just symptomatic of a maturing code base and software. The number of features also shows a steady decline, but in many ways newer features are more complex to implement. The pace of releases has remained constant.
View or Post Comments Roads and Bridges: The Unseen Labor Behind Our Digital Infrastructure
Roads and Bridges: The Unseen Labor Behind Our Digital Infrastructure
Monday, April 26, 2021
Having been involved in open source for the past 30 years, I have always felt like an outsider in social settings, having to explain the purpose of open source and its communities. (I remember having to
explain what email, Usenet, and the Internet were too, but that need has passed. )
It is not often that I get to learn something about open source from someone else, but this 143-page report by the Ford Foundation gives a very detailed review of the landscape and health of the open source ecosystem. It also highlights various challenges and how they might be addressed, many of which relate directly to Postgres and its continued health.
View or Post Comments Database Software Bundles
Database Software Bundles
Friday, April 23, 2021
When you buy a proprietary database from one of those billion-dollar companies, you get more than a database — you get backup, monitoring, high availability, and maybe scaling features. These all come from the same company, though some might require extra cost.
With Postgres, the story is more complicated. While the Postgres project produces an excellent, full-featured database, there are areas in backup, monitoring, and high availability where the project tooling doesn't meet everyone's needs, and users have to look outside the project for solutions. Sometimes other open source projects fill the gap, but in other cases Postgres companies do — Cybertec, edb, HighGo, Ongres, Postgres Pro, sra oss, and others often provide the last mile of service and solutions to meet enterprise needs.
Ideally the Postgres project would provide for all the software needed to run Postgres efficiently, but it is not clear there is a "one size fits all" solution for many of these needs, so having multiple groups is ideal because they can efficiently focus and adjust to those needs.
View or Post Comments Oracle vs. PostgreSQL
Wednesday, April 21, 2021
Following my blog entry about assumptions, this long email thread gives an interesting comparison of Oracle and Postgres. The original poster compares install times, initial database sizes, and relative bug counts. From there, things get complicated. There are various negative comments about the complexity of administering Oracle, and the simplicity of Postgres, but the discussion takes a turn when someone says comparing Postgres to Oracle is like comparing a rubber duck and 300,000 ton super tanker. He also states, "Oracle is also the single most feature-rich database out there — the feature set of Postgres isn't even 1% of what Oracle has."
It is actually good someone said that since it brought the discussion to a higher level where assumptions could be addressed. Someone easily disputed the 1% mention, and then got into a finer-grained comparison:
I'd say it's more in the vicinity of 80% or 90%, depending on which features you find more important, would be more realistic.But then Postgres has features that Oracle has not, like …
From a dba point of view, the percentage is probably lower than 80%, from a developer's point of view, Oracle lacks a lot of things and the percentage would be greater than 100%.
I thought that was interesting — to compare the dba and developer feature sets separately, and I think that is accurate. Also, when someone mentions over 100%, it makes it clear that there are useful features Postgres has that Oracle lacks. The email thread ends by discussing the lack of simple cross-database queries in Postgres. My previous blog post explained the use of multiple clusters, databases, and schemas; the mismatch between how Postgres and other databases handle these can be confusing.
View or Post Comments Challenging Assumptions
Monday, April 19, 2021
We all operate on assumptions, e.g., we expect to be alive tomorrow, we expect our family to always support us, we assume our car will start. Everyone needs to make some assumptions to function. But assumptions aren't always true, e.g., some day the sun will rise, and you will not be alive to see it. So, where does that leave us? We have to make assumptions to survive, but what we assume today might be false tomorrow. Fundamentally, successful people, while they rely on assumptions, are always alert for signs that their assumptions are false.
There are a number of assumptions about software that drive user behavior. While some of these assumptions might have been true in the past, they are now of questionable validity:
- Software that requires payment is always better than free software
- Open source code is less secure because it makes security flaws visible
- Open source isn't developed by serious people
- Oracle is the best database
- I will always be employed for my Oracle skills
People who actively question assumptions and regularly test their validity are more likely to take advantage of new opportunities, and I think the list above validates that. I often speak to current and prospective edb customers, and they ask many questions — sometimes I think they are going to ask questions forever. However, often the source of the questions is based on incorrect or no longer valid assumptions they have about the software world. I find that explicitly stating the assumptions, and explaining why they might no longer be valid, to be an effective way to get beyond specific questions. It helps them realize that Postgres is a great opportunity for their organizations, but only if they are willing to see the world as it is now, and not as it was.
View or Post Comments Rerouting Server Log Entries
Rerouting Server Log Entries
Friday, April 16, 2021
Postgres has a where, when, and what set of options to control database server log messages. One frequent request is to allow log message to be split into multiple files or sent to multiple servers. Postgres internally doesn't support this capability, but rsyslog, enabled with log_destination=syslog, allows complex filtering of database server log messages. Specifically, rsyslog's complex filters, combined with log_line_prefix, allows almost unlimited control over how log messages are recorded.
View or Post Comments The Power of Synchronous_commit
Wednesday, April 14, 2021
Postgres has a lot of settings — 329 in Postgres 13. Most of these settings control one specific thing, and the defaults are fine for most use-cases. Synchronous_commit is one of the settings that isn't simple and controls perhaps too many things, though there are operational restrictions which prevent it from being split into separate settings.
In fact, this setting is so complex that when I started to research what it controls, I realized our existing documentation was not completely clear on all of its capabilities. Therefore, I rewrote this setting's documentation in October of 2020, and the updated documentation was released in our November 12th minor releases. As you can see from the table added to the docs, synchronous_commit controls not only the local durability of commits, but also standby behavior.
First, let's focus on its local behavior, that is, without considering standby servers. The value off causes synchronous_commit to not wait for the records associated with the commit to be written to the write-ahead log. It does, however, guarantee data consistency, meaning, that in the event of a crash, the transactions it does recover will be consistent with each other. It just doesn't guarantee that all committed transactions will be restored in the event of a crash. This is in contrast to the setting fsync=off, which does not guarantee data consistency, meaning, after an operating system crash, some transactions might be partial or inconsistent with other records.
The local option waits for the commit to be durably recorded, meaning any crash recovery will restore all committed database changes. All the other options add waiting for standby servers, while synchronous_standby_names controls which or how many standby servers to wait for. The synchronous_commit option remote_write waits for one or more standby servers to have their transaction information durably stored in case of a Postgres crash. Option on (the default) is similar to remote_write but is durable against standby operating system crashes, not just Postgres crashes. Option remote_apply waits for the transaction to be replayed and visible to future read-only transactions on the standby server. (I covered the details of when commits are visible in a previous blog entry.)
Given the scope of synchronous_commit, you might assume changing it requires a server restart. On the contrary, it can be set to different values in different sessions on the same server, and can be changed during sessions. Yeah, kind of crazy, but it works, and it allows you to control transaction durability and visibility depending on the importance of the transaction. As Postgres covers in its documentation, while Postgres is a fully durable relational database, it does allow fine grained control over the durability and even standby visibility of transactions.
View or Post Comments Shared Memory Sizing
Shared Memory Sizing
Monday, April 12, 2021
Postgres makes extensive use of operating system shared memory, and I have already written a presentation about it. The Postgres documentation gives specific instructions on how to determine the amount of shared memory allocated, specifically for sizing huge pages.
However, exactly what is inside Postgres shared memory was somewhat of a mystery to end users until Postgres 13 added pg_shmem_allocations, which gives a detailed list of the uses and sizes of allocated shared memory:
SELECT *, pg_size_pretty(allocated_size) FROM pg_shmem_allocations ORDER BY size DESC;
name | off | size | allocated_size | pg_size_pretty
-------------------------------------+------------+------------+----------------+----------------
Buffer Blocks | 69908224 | 6442450944 | 6442450944 | 6144 MB
Buffer Descriptors | 19576576 | 50331648 | 50331648 | 48 MB
<anonymous> | (null) | 43655168 | 43655168 | 42 MB
Buffer IO Locks | 6512359168 | 25165824 | 25165824 | 24 MB
Checkpointer Data | 6597411712 | 18874432 | 18874496 | 18 MB
XLOG Ctl | 53888 | 16803472 | 16803584 | 16 MB
Checkpoint BufferIds | 6537524992 | 15728640 | 15728640 | 15 MB
Xact | 16857856 | 2116320 | 2116352 | 2067 kB
(null) | 6616370560 | 1921664 | 1921664 | 1877 kB
Subtrans | 19107968 | 267008 | 267008 | 261 kB
CommitTs | 18974208 | 133568 | 133632 | 131 kB
MultiXactMember | 19441792 | 133568 | 133632 | 131 kB
Serial | 6596798464 | 133568 | 133632 | 131 kB
Backend Activity Buffer | 6597153664 | 132096 | 132096 | 129 kB
shmInvalBuffer | 6597332864 | 69464 | 69504 | 68 kB
Notify | 6616303744 | 66816 | 66816 | 65 kB
MultiXactOffset | 19374976 | 66816 | 66816 | 65 kB
Backend Status Array | 6597082240 | 54696 | 54784 | 54 kB
Backend SSL Status Buffer | 6597285760 | 42312 | 42368 | 41 kB
Shared Buffer Lookup Table | 6553253632 | 33624 | 33664 | 33 kB
KnownAssignedXids | 6597042560 | 31720 | 31744 | 31 kB
ProcSignal | 6597403392 | 8264 | 8320 | 8320 bytes
Backend Client Host Name Buffer | 6597145344 | 8256 | 8320 | 8320 bytes
Backend Application Name Buffer | 6597137024 | 8256 | 8320 | 8320 bytes
KnownAssignedXidsValid | 6597074304 | 7930 | 7936 | 7936 bytes
AutoVacuum Data | 6616286208 | 5368 | 5376 | 5376 bytes
Background Worker Data | 6597328256 | 4496 | 4608 | 4608 bytes
Fast Path Strong Relation Lock Data | 6594531840 | 4100 | 4224 | 4224 bytes
PROCLOCK hash | 6593836672 | 2904 | 2944 | 2944 bytes
PREDICATELOCK hash | 6594981376 | 2904 | 2944 | 2944 bytes
SERIALIZABLEXID hash | 6596446976 | 2904 | 2944 | 2944 bytes
PREDICATELOCKTARGET hash | 6594536064 | 2904 | 2944 | 2944 bytes
LOCK hash | 6593141504 | 2904 | 2944 | 2944 bytes
Async Queue Control | 6616301184 | 2492 | 2560 | 2560 bytes
ReplicationSlot Ctl | 6616291584 | 2480 | 2560 | 2560 bytes
Wal Receiver Ctl | 6616295936 | 2248 | 2304 | 2304 bytes
BTree Vacuum State | 6616298880 | 1476 | 1536 | 1536 bytes
Wal Sender Ctl | 6616294784 | 1040 | 1152 | 1152 bytes
Shared MultiXact State | 19575424 | 1028 | 1152 | 1152 bytes
PMSignalState | 6597402368 | 1020 | 1024 | 1024 bytes
Sync Scan Locations List | 6616300416 | 656 | 768 | 768 bytes
ReplicationOriginState | 6616294144 | 568 | 640 | 640 bytes
Proc Array | 6597041920 | 528 | 640 | 640 bytes
Logical Replication Launcher Data | 6616298240 | 424 | 512 | 512 bytes
Control File | 16857472 | 296 | 384 | 384 bytes
Proc Header | 6596932224 | 104 | 128 | 128 bytes
PredXactList | 6596241792 | 88 | 128 | 128 bytes
OldSnapshotControlData | 6616298752 | 68 | 128 | 128 bytes
CommitTs shared | 19107840 | 32 | 128 | 128 bytes
Buffer Strategy Status | 6593141376 | 28 | 128 | 128 bytes
RWConflictPool | 6596505344 | 24 | 128 | 128 bytes
FinishedSerializableTransactions | 6596798336 | 16 | 128 | 128 bytes
Prepared Transaction Table | 6597328128 | 16 | 128 | 128 bytes
SerialControlData | 6596932096 | 12 | 128 | 128 bytes
The null name is unused shared memory. Summing the allocated_size column yields a number similar to the output of pmap, which is described in the documentation above. On my system, pmap is ~1% higher than allocated_size, probably because shared library memory is also counted by pmap.
View or Post Comments Replica Scaling by the Numbers
Replica Scaling by the Numbers
Friday, April 9, 2021
I have previously blogged about scaling of read-only and read/write workloads. Inspired by this email thread, I want to be more specific about exactly what scaling you can expect by using read-only replicas. First, as the email poster pointed out, read replicas still have to replay write transactions from the primary server. While the replica servers don't need to execute the write queries when using binary replication, they still need to perform the heap/index writes that the primary performs. (Logical replication does add significant cpu overhead.)
Let's look at rough numbers of the load on binary-replication replicas. Suppose the write load on the primary is 30% — that leaves 70% of the i/o for read-only queries, and even more than 70% of the cpu capacity since binary replication replay uses much less cpu than running the actual write queries. If there are three replicas, that means you have 210% of the primary's read-query capacity available on the replicas.
However, if you have a 75% write load on the primary, you only have an extra 25% capacity on the replicas, so your scaling ability is much more limited — it would take four replicas just to double the read capacity of the primary. This explains why high write workloads only effectively scale read-only processing using sharding.
View or Post Comments Operating System Choice
Wednesday, April 7, 2021
In the 1990's, most server operating systems were closed-source and produced by a few billion-dollar companies. In recent years, Red Hat Enterprise Linux (rhel) became the default enterprise server operating system, with centos filling the need for installations on smaller platforms and in the cloud. (Centos was sometimes the only operating system used.) With the move of centos away from being a stable releases tracking rhel, there is renewed interest in other operating systems.
There are many viable operating system choices, and with so many choices, selection can be difficult. When choosing an operating system to host a database like Postgres, there are some important criteria:
- Does the operating system have a server focus, or desktop/laptop/mobile focus?
- How easy is it to administer, and does your staff have the appropriate skills?
- What support options are available? What is the operating system's support life span?
- Are upgrades easily handled? How often do operating system upgrades require rebooting?
- Is the operating system easily installed on developer workstations, laptops, and smaller devices?
- Is there sufficient hardware support? Is performance acceptable?
- Is cloud deployment easy?
Once you deploy a database like Postgres on an operating system, changing operating system can require significant testing and disruption, so it is wise to choose the right operating system at the start. While I didn't mention the operating system's license before, the license can often influence the items listed above, like easy installation on smaller hardware and in the cloud, and multiple support providers. Debian, Ubuntu, FreeBSD, Fedora, Suse, Rocky Linux, and others are all going to have different strengths. I think the above bulleted list is a good start in evaluating those options. Fortunately, Postgres is supported by all popular operating systems, so Postgres should not be a limiting factor in choosing an operating system.
View or Post Comments Many Upgrade Methods
Monday, April 5, 2021
Databases are often a critical part of enterprise infrastructure, so when and how to upgrade them is a common discussion topic among database administrators, and Postgres is no exception. The Postgres community has a web page about when to upgrade, and the Postgres documentation has a section about upgrading.
Minor upgrades with Postgres are simple. Though three primary major version upgrade methods are listed in the documentation, there are actually eight possible options:
- pg_dumpall/restore
- pg_dump/restore databases serially
- pg_dump/restore databases in parallel
- pg_dump/restore in parallel mode and databases serially
- pg_dump/restore in parallel mode and databases in parallel
- pg_upgrade in copy mode (with optional parallel mode)
- pg_upgrade in link mode (with optional parallel mode)
- Logical replication
Options 1–5 are based on pg_dump/pg_dumpall, options 6 & 7 use pg_upgrade, and #8 uses logical replication. The big question is which option to choose. Option one is the simplest and ideal for small clusters that can tolerate the downtime of serially dumping and reloading. Options 3–5 use the same method as 1 & 2 but allow parallelism in dump and restore. It can be tricky to figure out which databases to dump/reload in parallel, and how much parallelism to specify for each dump/restore operation — you basically have to figure out how to fully utilize the cpu and i/o resources without overwhelming them and making things slower. I wish there were simple rules people could follow when specifying parallelism but I have never seen them; it is probably necessary to do performance testing of various options.
Options 6 & 7 use pg_upgrade which can rapidly perform upgrades with minimal downtime. Option 6 allows restarting the old server even after the new server is started, but requires copying all of the user heap and index files, which can be slow. Option 7 can be very fast and its speed depends primarily on how quickly it can create empty user objects — terabyte upgrades can be performed in minutes. It also is the only option that doesn't require twice as much storage space for the upgrade. Options 6 & 7 do not remove bloat that might exist in the old cluster.
Option 8 uses logical replication, which requires significant configuration, but the upgrade can be very quick, even faster than pg_upgrade.
Hopefully this blog post has improved your understanding of available options for Postgres major version upgrades. Here are the criteria you need to consider when choosing an upgrade method:
- Reliability/simplicity: 1 & 6
- Minimal downtime: 7 & 8
- Limited storage required: 7
- Bloat removal: all but 6 & 7
 RSS
RSS{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}